今天遇到一个需求,需要随机的生成一个枚举类型的实例。
不像 Python 那样方便,用 Rust 需要实现特定的 Trait,最简单的想法就是给枚举类型不同的成员编个号,然后生成一个随机数,实例化对应的成员,如果成员拥有数据,就递归的随机生成这些数据。
1
2
3
4
5
6
7
8
9
10
11
12
| impl Distribution<Instruction> for Standard {
fn sample<R: rand::Rng + ?Sized>(&self, rng: &mut R) -> Instruction {
match rng.gen_range(0..459) {
0 => Instruction::Unreachable,
1 => Instruction::Nop,
2 => Instruction::Block(BlockType::FunctionType(rng.gen())),
3 => Instruction::Catch(rng.gen()),
// ... 预估超过2千行
_ => unreachable!(),
}
}
}
|
需求本身确实简单,问题在于这个枚举类型的成员太多了,足足有 459 个,按照传统的思路,保守估计至少要写半天,并且很枯燥。图中可以看出,要对该枚举类型实现一个简单的函数都需要上千行。
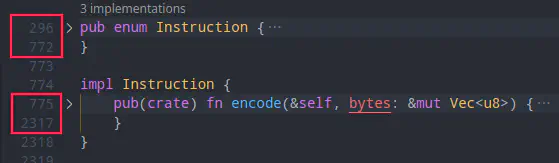 庞大的枚举类型
庞大的枚举类型
我非常讨厌这种简单却繁重的工作的,我想到了 Rust 过程宏。
当初学 Rust 的时候,了解过 宏 相关的内容,其中 声明宏 技术我已经在其他项目中实践过了,因为其本身就是个模板生成代码,所以无法满足我这次的需求。而过程宏可以通过编写函数,对代码本身进行解析和处理,在抽象语法树的基础上进行操作,所以可以实现非常复杂的逻辑,是代码生成方面的绝佳工具。
过程宏的编写比较费脑子,写一个自动生成代码的过程宏可能会让我掉几根头发。但相比较写几千行枯燥代码浪费生命,我还是更愿意舍弃掉这几根头发。并且我还惊奇的发现,rand 库在 0.5 版本的时候曾经实现过类似的过程宏,可以给任意的结构、元组和枚举实现 Rand,虽然已经不维护了,但是可以给我借鉴。
我的需求是根据 Instruction 的成员信息,自动实现 impl Distribution<Instruction> for Standard,这里就需要写一个 #[derive]宏,使其作用在 Instruction 上。
1
2
| #[derive(Debug, Rand)]
pub enum Instruction {...}
|
首先定义名为 Rand 的 #[derive]过程宏。在这个函数里,我们可以拿到 Instruction 的 token 序列,然后将其解析为抽象语法树 (AST),最后通过 AST 和我们的逻辑生成新的 token 序列,即最终生成的代码。
1
2
3
4
5
6
| #[proc_macro_derive(Rand)]
pub fn rand_derive(input: TokenStream) -> TokenStream {
let ast = parse_macro_input!(input as DeriveInput);
let tokens = impl_rand_derive(&ast);
TokenStream::from(tokens)
}
|
对于将 token 序列解析为 AST,社区普遍使用的是 syn 库,而将 AST 的数据结构还原成 token 序列一般使用 quote 库,今天搜的时候我惊奇的发现这两个库都是 David Tolnay 开发的。看了一下 他在crates.io发布的库,真是强者恒强,建议自己去看一下,然后疯狂膜拜
在拿到抽象语法树后,顶层便是 Instruction,根据思路我们应该遍历其所有的成员,分析成员的类型并根据相关信息生成代码。
成员可能有三种类型:
- Named: 带名称的,类似于
Named { x: u8, y: i32} - Unnamed: 不带名称的,类似于
Unamed(u8, i32) - Unit:
() 类型
对于 Named 和 Unamed 两种类型,都需要遍历其所有元素,递归的生成代码,用 __rng.gen() 来初始化数据。
最后判断枚举类型成员数量,生成 match 语句。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| let rand = if let syn::Data::Enum(ref data) = ast.data {
let ref virants = data.variants;
let len = virants.len();
let mut arms = virants.iter().map(|variant| {
let ref ident = variant.ident;
match &variant.fields {
syn::Fields::Named(field) => {
let fields = field
.named
.iter()
.filter_map(|field| field.ident.as_ref())
.map(|ident| quote! { #ident: __rng.gen() })
.collect::<Vec<_>>();
quote! { #name::#ident { #(#fields,)* } }
}
syn::Fields::Unnamed(field) => {
let fields = field
.unnamed
.iter()
.map(|field| quote! { __rng.gen() })
.collect::<Vec<_>>();
quote! { #name::#ident (#(#fields),*) }
}
syn::Fields::Unit => quote! { #name::#ident },
}
});
match len {
1 => quote! { #(#arms)* },
2 => {
let (a, b) = (arms.next(), arms.next());
quote! { if __rng.gen() { #a } else { #b } }
}
_ => {
let mut variants = arms
.enumerate()
.map(|(index, arm)| quote! { #index => #arm })
.collect::<Vec<_>>();
variants.push(quote! { _ => unreachable!() });
quote! { match __rng.gen_range(0..#len) { #(#variants,)* } }
}
}
} else {
unimplemented!()
};
|
紧接着就会发现,上面在 Named 和 Unamed 的部分进行递归 __rng.gen(),需要其使用的类型也实现相应的 trait。除去已有的对基本类型的实现外,剩下的类型就需要我们手动实现,这也就要求我们的过程宏也能应用在其他结构上。
因此我们的函数需要进行修改,以处理其他非枚举类型:结构体和元组(元组在我的需求中没用到,就不实现了)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| let rand = match ast.data {
syn::Data::Struct(ref data) => {
let fields = data
.fields
.iter()
.filter_map(|field| field.ident.as_ref())
.map(|ident| quote! { #ident: __rng.gen() })
.collect::<Vec<_>>();
quote! { #name { #(#fields,)* } }
}
syn::Data::Enum(ref data) => {
// 刚刚的方法拿进来
}
_ => unimplemented!(),
};
|
测试,发现 459 个成员通过了 458 个,剩下的那一个成员是 Cow 类型的。是真的烦,没办法给 Cow 实现这个 trait,甚至理论上根本没办法生成一个随机的 Cow,因为其根本不拥有数据,它只有指针。
我马上想到了一个解决方案,牺牲一点性能,用 Vec 替换掉 Cow。虽然我们仍然无法给 Vec 实现这个 trait(因为 Vec 是外部定义的),但是我可以在解析的时候判断一下类型,如果是 Vec 就手动生成随机长度的随机数据,我真是个小机灵鬼。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| let fields = field
.unnamed
.iter()
.map(|field| {
if inner_type_is_vec(&field.ty) {
quote! {{
let i = __rng.gen_range(0..100);
__rng.sample_iter(::rand::distributions::Standard)
.take(i)
.collect()
}}
} else {
quote! { __rng.gen() }
}
})
.collect::<Vec<_>>();
fn inner_type_is_vec(ty: &syn::Type) -> bool {
if let syn::Type::Path(syn::TypePath { ref path, .. }) = ty {
if let Some(seg) = path.segments.last() {
return seg.ident == "Vec"
}
}
false
}
|
测试,全部通过!开心!
学习过程宏,写过程宏、写测试用例,到最后测试通过,着实花了不小功夫。原本还挺有成就感的,直到刚刚,我发现虽然 rand 不再维护这个 derive宏了,但是有一个第三方维护的版本,测试了一下,除了有几个测试用例过不了,在我目前的需求上完全可用。真是痛苦,如果早点发现就好了,又是造轮子的下午。不过幸亏最终结果是好的,通过编写过程宏,用 100 行代码完成了需要 2k+ 行代码的任务,最重要的是不再枯燥。
Rust 的宏机制真的强大,利用好可以做很多有意思的事。例如目前的变长参数函数还有序列化反序列化,在Rust中都是通过过程宏实现的。通过过程宏可以将其他语言中很多需要在运行时进行的工作提前到编译期进行,明显的提高了Rust程序的性能和灵活性,为我们提供了强大的表达和实现能力。
我突然想到,可以用宏来做代码混淆和字面量加密,后面尝试一下。